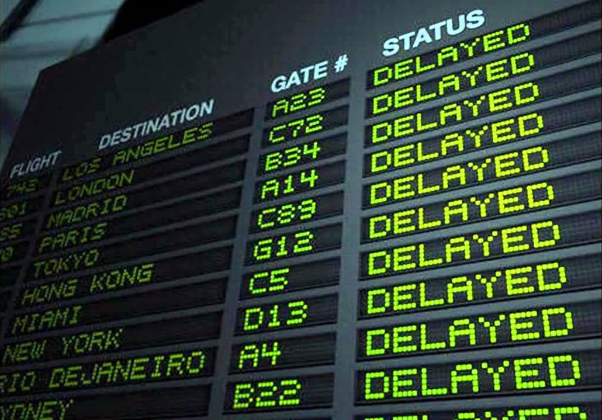
This summer’s outages at Delta and Southwest have much to teach all of us in IT.
It has not been a good few months for the health and consistency of airline information technology. Two huge outages within a couple of weeks of each other — caused by simple component failures — resulted in massive passenger disruptions and cost two U.S. airlines millions of dollars in lost revenue and customer compensation.
First, a little background. What ended up being a faulty router took down the entire Southwest Airlines operation for a day on July 21 and caused rippling effects for several days after the original outage. (A fact that might surprise you is that Southwest is by a wide margin the largest domestic carrier of passengers in the United States.) The Dallas Morning News reported the fallout.
“The outage occurred early Wednesday afternoon after a network router failed and the backup systems failed to kick in,” the newspaper reported. “Although the outage was fixed about 12 hours later, the scale of the disruption wreaked havoc on Southwest’s operations for the next several days as the Dallas-based carrier worked to get planes, crews and passengers where they were supposed to be.” In total, the airline said it canceled about 2,300 flights, or around 11% of the total it would have otherwise operated in that time frame.
(The line “backup systems failed to kick in” will ring familiar to Amazon Web Services customers, as a similar failure of backup systems took out much of Amazon’s cloud hosting operation back in 2011 and really kickstarted the process of using Amazon’s availability zones and other fault-tolerance features among cloud customers.)
Then, a couple of weeks later, on August 8, it was Delta Air Lines’ turn at the Wheel of IT Outages, with hundreds of canceled and delayed flights during the middle of its demanding summer travel season, all due to an electrical component failure. The Wall Street Journal reported the story thusly: “An electric problem at its Atlanta headquarters occurred at 2:30 a.m. ET and the airline was forced to hold hundreds of departing planes on the ground starting at 5 a.m., according to Ed Bastian, the chief executive, who apologized to customers on a video. The technical problems likely will cost Delta millions of dollars in lost revenue and damage its hard-won reputation as the most reliable of the major U.S.-based international carriers, having canceled just a handful of flights in the most recent quarter.”
Apparently the underlying technology issue at fault in the Delta outage was a switchbox — essentially a giant fuse box that routes power into and out of a facility — that failed at Delta’s headquarters, according to Georgia Power, the public utility that supplies electricity to the location in question. What is not clear is why an outage that occurred at 2:30 a.m. was not able to resolve in time for flights to begin being dispatched at 5:00 a.m., nor why the cascading delays from the 5:00 a.m. cancellations could not have been less severe, or why they could not have been rectified more quickly.
What does all of this mean?
The Delta and the Southwest outages show how a single IT failure at the wrong place at the wrong time — still, even after all of these years of planning and talk of the importance of disaster recovery — can quickly cost millions, even in the course of just hours.
via:http://www.computerworld.com/article/3114125/backup-recovery/lessons-from-high-profile-it-failures.html


